Deep Learning on a Mac with AMD GPU
Since Apple is only providing AMD GPUs in its computers, Data Scientist working on MacOSX are facing limitations when trying to train Deep Learning models.
Three solutions exist
- Buy a eGPU Box and a NVidia card, but while NVidia is not officially supported by Apple today it could be quite unstable and every OS or framework upgrade will be subject to very long operations (like compiling every new release of tensorflow in GPU mode)
- Boot on Linux, with an external SSD or a double boot then use AMD ROCm
- Using Keras with PlaidML, an OpenCL compatible backend
As the third solution is by far the simplest and less intrusive option I’ve decided to rely on it as far as possible for most of my daily work. For the cases that cannot be managed by this solution and for long training, I continue using Floydhub as my main GPU Cloud.
The only question for me was to validate PlaidML performances compared to running TensorFlow on CPU.
I’ve started to test both and their different versions by training the same very simple ConvNet on the MNIST dataset.
All the tests are performed on a iMac 27 Mid 2017, Core i5 3.8 GHz. The internal GPU is a Radeon Pro 580.
I’ve run the following very simple ConvNet on MNIST, on 5 epochs only with a quite small batch size of 64 avoiding harming too much the CPU compared to the GPU.
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape=(28,28,1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(10,activation='softmax'))
model.compile(optimizer = 'rmsprop',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])The table below summarizes my test results with TensorFlow on CPU and PlaidML on the GPU.
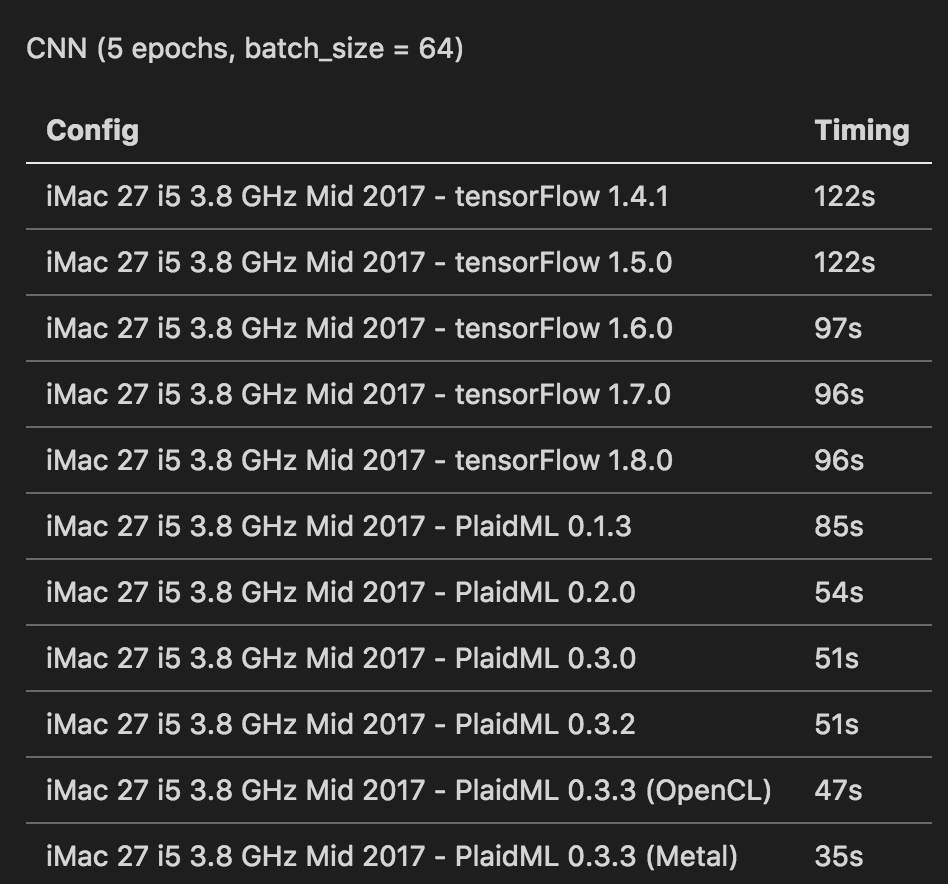
The first important thing is that TensorFlow CPU performances were improved by 20% since version 1.6.0.
This can be explained by the compilation optimizations.
With TF 1.5.0 :
Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.2 AVX AVX2 FMA
With TF 1.6.0 :
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
PlaidML release 0.3.3 introduced the Metal support to Radeon GPU in addition to OpenCL. As shown by the benchmark, this configuration is 2.74 times faster than TensorFlow 1.8 CPU version.
Of course, using a GPU enables taking benefits of BatchSize increases. In this case PlaidML 0.3.3 Metal was performing the training in 21 seconds, so 4.57 times faster than TF 1.8 CPU version.
Note the very last tests (TF 1.8.0 and PlaidML 0.3.3) were performed with Keras 2.2.0
Today I train most of my small and medium Deep Learning models directly on the Mac without having to go to Cloud GPU services. This makes my iterations quicker and research process much more comfortable.
I hope this short benchmark will help many other Data Scientists also working on MacOSX.
Thank you for reading.
